
Since the organization consolidates the workload of analysts on databricks, they often have to adapt traditional data warehouse techniques. This series examines how to implement Dimensal modeling – specifically Star Schomas – We databricks. The first blog focused on the design of the scheme. This blog passes the ETL pipeline for dimensions tables, included a slowly changing dimension (SCD) Type-1 and Type-2 patterns. The last blog will show you how to build an ETL pipe for fact tables.
Slowly changing dimensions (SCD)
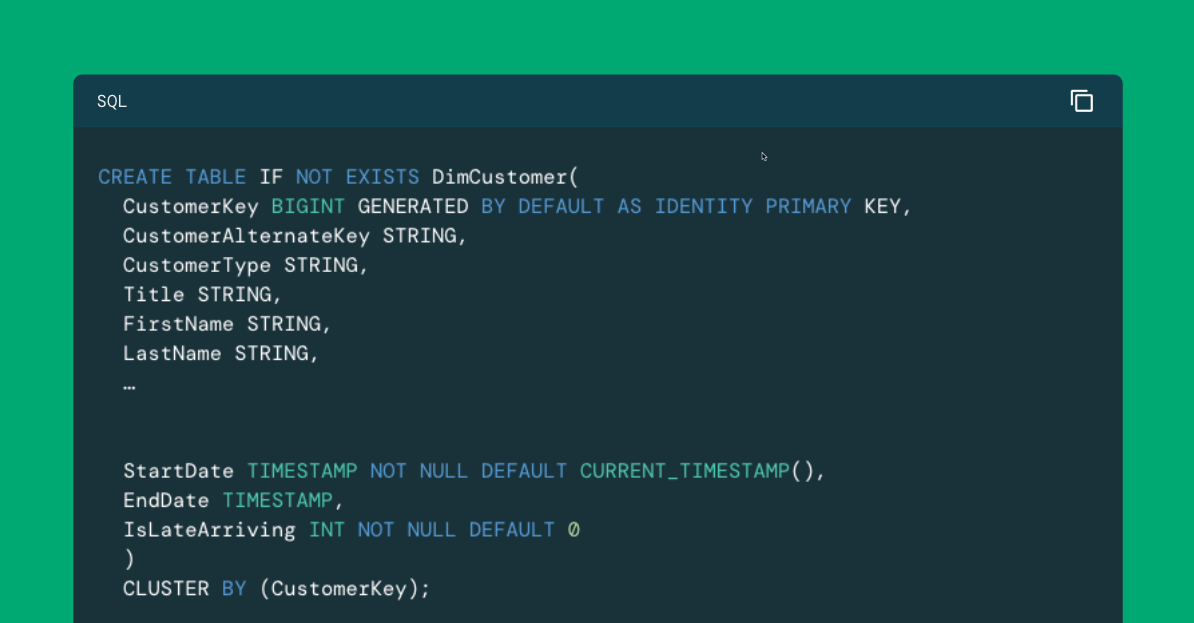
IN Last blogWe defined our stellar scheme, included a table of facts and its related dimensions. We emphasized in particular one dimensional table, Dimcustomer, as shown here (with some attributes removed to maintain space):
The last three fields in this table, i.e, Start Date,, Enddat and IslatearrivingIt attracts metadata, which helps us with record versions. As the income of the customer, family status, ownership of the house, the number of children at home or other characteristics, we will want to create new records for this customer, so Faies like our online dirty transactions False They are associated with the correct representation of this customer. Tea The key of natural (aka),, Custoralternatekeywill be the same in these records, but metadata will vary, allowing us to know the period for which this version of the customer was valid as it will be Key replacement,, CustomerkeyAllowing our facts to refer to the right version.
NOTE: Because the replacement key is commonly used to connect facts and dimensions, the table of dimensions are often rolled based on this key. In contrast to relational traditional databases that use B-strom indices on sorted records, Databricks implements the unique clustering method known as as as Liquid cluster. While the specifics of the liquid cluster are outside the range of this blog, we consistently use the clause of the clause of the clause on the replacement key of our dimensions, which dares their definition to use this function effective.
This formula of the dimension of versions as a change in attribute Type-2 slowly changing size (Gold simply SCD type 2). The SCD type 2 pattern is preferred to record dimensions in classical dimensional methodology. However, there are other ways to deal with changes in dimensions.
One of the most common ways to deal with changing dimension values is to update existing records. Only one version of the record is always created, so the business key remains a unique recording identification. For various reasons, last but not least, performance and consistency are, we are still implementing a replacement key and connecting our facts with these dimensions on these keys. Yet, Start Date and Enddat The metadata fields that describe the time intervals in which the record dimension is considered active is not necessary. This is known as Type 1 SCD pattern. Dimension Promotion in our Star Schema provides a good example of implementation of the type of dimension table: Type-1:
But what Islatearriving The metadata field is seen in the customer dimension type 2, but is missing in the dimension of type 1 promotion? This field is used to indicate records on late arrival. Has Late Recording Record It is the one for which the business key occurs during the ETL cycle, but there is no record for this key located during the previous dimension processing. In the case of type 2 SCDS, this field is used to indicate that late arrival data is observed for the first time in the ETL Dimension cycle, the record should be updated on site (as in the SCD type 1), and then the SCD 1 version is not required because the record will be updated.
NOTE: The Kimbball Group recognizes other SCD patterns, most of which are variations and combinations of type-2 and type 2 patterns. Because the SCD-1 and type 2 SCDs are most often implemented from these patterns and techniques used with others closely related to what is employed with them, we limit this blog to these two dimensions. For more information about eight types of SCD recognized by Kimball group, please A slowly changing technical dimension part This document.
Implementation of SCD Sample Type 1
With the data update on the spot, the formula of the 1 SCD working process is the simplest of the two dimensional ETL patterns. To support these types of dimensions simply:
- Extract the required data from our operating system (systems)
- Perform any required data cleaning operations
- Compare our incoming records with those that are already in the table dimension
- Update all existing records where attributes recorded differ from what is already recorded
- Insert any incoming records that do not have a corresponding record in the dimension table
To illustrate the implementation of SCD type 1 we define ETL for nail population Dimpromotion table.
Step 1: Extract data from the operating system
Our first step is to extract data from our operating system. Since our data warehouse is patterned after a sample database AdventureWorksDW provided by Microsoft, we use closely related Sample database AdventureWorks (OLTP) As far as the source is concerned. This database has been deployed to the instance of the Azure SQL database and made available in our databricks environment via a Federal question. Extraction is then facilitated by a simple query (with some fields decorated to maintain space), with the results of the query persisted in the table in our table performance Scheme (this is made available only to data engineers in our surroundings via the permits settings that are not displayed here). This is just one way we can get access to the source system data in this environment:
Step 2: Compare incoming records with records in the table
If we have no further steps to clean data (which we could implement with Update gold Create a table as Stamente), we can do this Operations update/insert data in one step using a Mound StemmentThat corresponds to our staged data and dimensions on the commercial key:
One important thing that needs to be noted about the stament, as written here, is that we update all existing records when a match between the stage and the published data is found. We could add more criteria to the WHO clause to limit updates to cases where the record has different information from what is in the dimension table, but due to the relatively small number of records in this particular table, we decided to employ relatively slimmer logic. (Next we use when it matches the logic with Dimcustomer, That contains much more data.)
SCD type 2 pattern
SCD type 2 SCD is a bit more complicated. To support these types of dimensions, we have to:
- Extract the required data from our operating system (systems)
- Perform any required data cleaning operations
- Update all records of a member coming late in the target table
- Existing records expire in the target table for which new versions are in staging
- Insert any new (or new versions) records in the target table
Step 1: Extract and clean the data from the source system
As in the SCD type 1 formula, our first steps are to extract and clean data from the source system. Using Appopach, as mentioned above, we come to a federated question and the next creation and table in our performance plan:
Step 2: Compare to the table dimension
With this data landing, we can now compare them with our dimension table to make any required data editing. The first is to update all the records marked on late from the previous ETL table processes. Please note that these updates are limited to those records marked as late arrival and Islatearriving The symptom is reset with the update, so these records behave like a normal SCD type 2 progressing:
Step 3: The version of the records expires
Another set of data changes is the expiry of all records that are needed. It is important that Enddat the value we set for these matches Start Date We will implement the new versions of the records in the next step. For this reason we set the time stamp variable be used between the following two steps:
NOTE: Depending on the available data, you can choose to employ Enddat The value of the original from the source system where you would not require you to declare a variable here, as you show here.
Please take note of other criteria used in the WHOS SPATED clause. Since we are only a performer one operation with this statement, it would be possible to move this logic to the ON clause, but we kept it separately from the logic of the basic matches, where we match the current version of the dimension for clarity and maintaining.
We use very much in this logic Equice_Null () Function. This function returns the truth when the first and second values are the same or both zero; Otherwise, False returns. This provides an effective way to look for changes based on the column. For more information on how databricks support zero semantics please pass on This document.
On this internship, all previous versions of the records in the dimensions that have expired were finally dated.
Step 4: Put new records
Now we can insert new records, truly new and new versions:
As before, it could be implemented using InsertBut the result is the same. With this statement, we have identified any records in the production table that you have a non -expired record in the dimensions tables. These records are simply inserted SA Start Date The value consists of any expired records that may exist in this table.
Next steps: Implementation of the ETL fact table
With implemented and filled data, dimensions can now be focused on tables of facts. In the next blog, we will show how the ETL can be implemented for these tables.
You want to know more about databricks sql, visit our Site Now read the documentation. You can also see Tour of the product for databricks sql. Suppose you want to migrate your existing warehouse for a high -performance and server without a server with a great user experience and a lower total number of costs. In this case, the solution of the databricks SQL – the solution – is Try it free of charge.